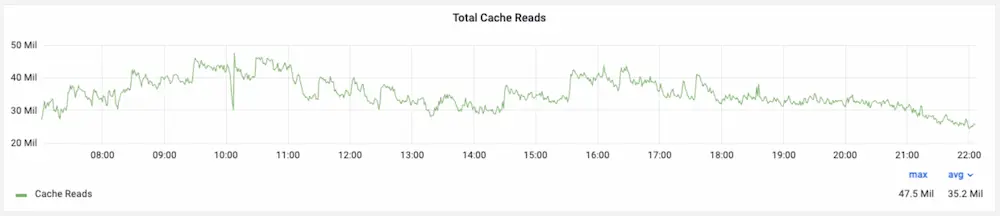
Uber integrated cache technology is a game-changer, enabling the platform to handle over 40 million reads per second while keeping data delivery lightning fast.
Introduction to Uber Integrated Cache
When you open the Uber app and check your ride history, driver location, or fare details, the response is almost instant. Behind the scenes, Uber’s systems handle over 40 million read requests every second—without breaking a sweat.
In this post, we’ll break down how Uber built CacheFront, the caching system that powers lightning-fast reads while keeping data fresh and accurate.
Step 1: The Data Backbone – Docstore
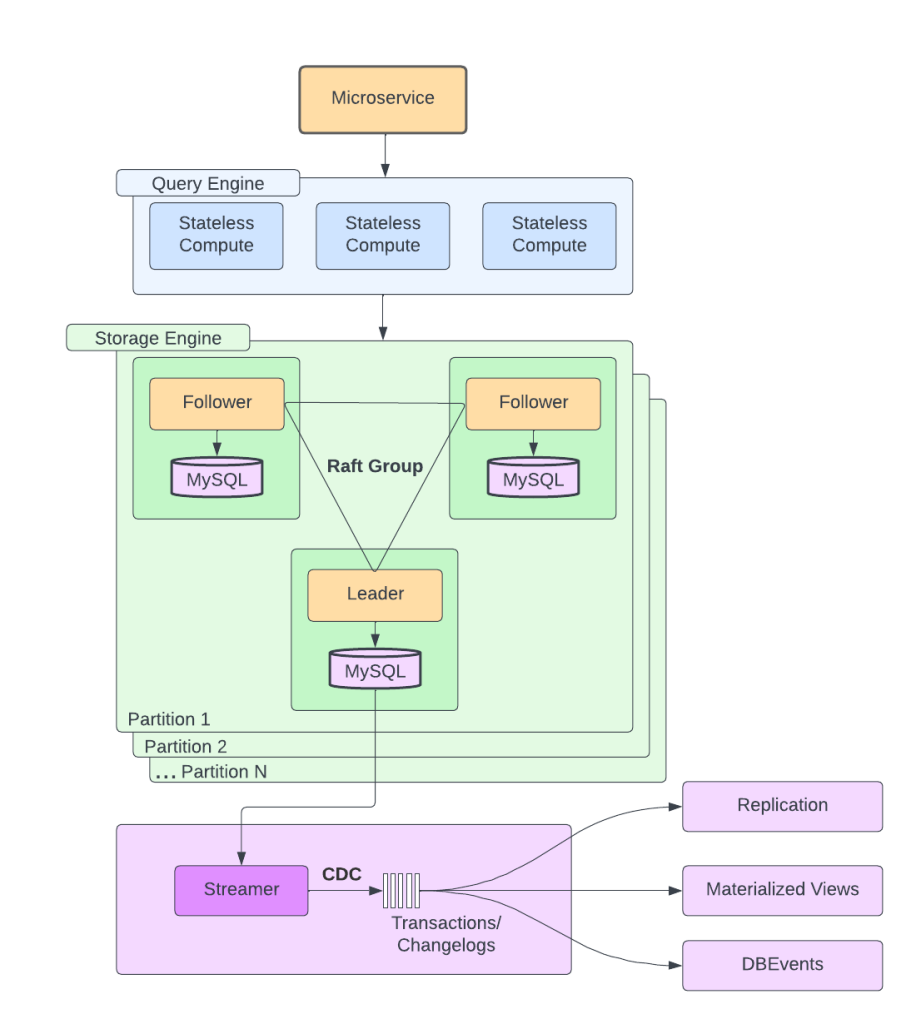
Uber’s Docstore is a distributed MySQL-based storage system designed to handle petabytes of structured data. It’s built for:
- High reliability
- Multi-region replication
- Flexible querying for multiple Uber services
But as demand grew, simply reading from databases—no matter how optimized—wasn’t fast enough.
Step 2: What Is CacheFront? Uber’s Redis-Powered Integrated Cache
CacheFront is Uber’s integrated caching system, built using Redis and tightly connected to Docstore’s query engine.
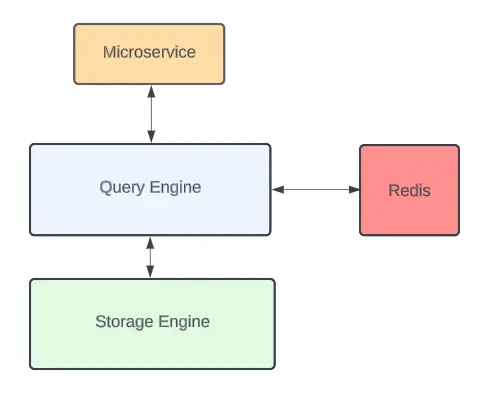
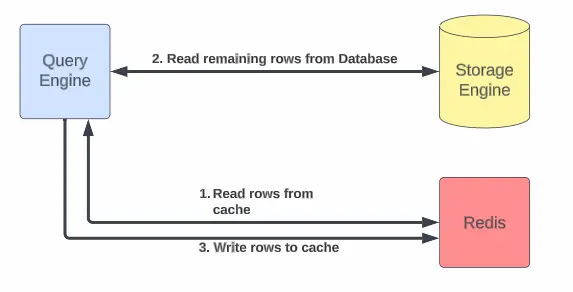
How It Works (Cache-Aside Pattern):
- Check Redis first → If data is in cache, return it instantly.
- Cache miss? → Fetch from Docstore, then store it in Redis for next time.
Step 3: Keeping Data Fresh – CDC & Flux
Instead of relying on time-to-live (TTL) to expire cache entries, Uber uses Change Data Capture (CDC) through a system called Flux.
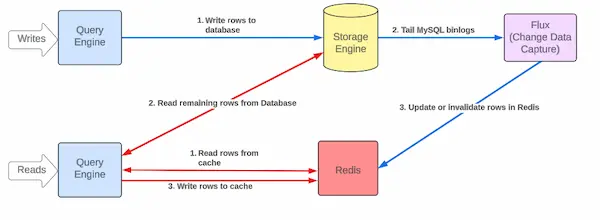
Here’s what happens:
- Flux listens to MySQL binlogs for changes.
- When a record changes, Flux updates or invalidates the cache in seconds.
- This ensures accuracy even during high traffic.
Note: CacheFront uses version numbers for each row, so stale data can’t overwrite newer updates.
Step 4: Scaling Globally – Uber integrated cache
Uber’s cache solution had to work across multiple regions.
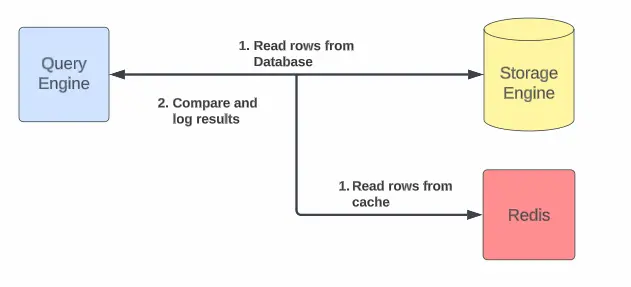
They solved this with:
- Cache Warmup Across Regions → When data is cached in one region, the key is sent to others to pre-fetch the same data.
- Compare Cache Mode → Reads are tested against both cache and DB to check for mismatches (Uber achieved 99.99% consistency).
- Independent Sharding → Cache shards are not tied to database shards, reducing the risk of overload when a cache node fails.
Uber integrated cache: Results & Performance Impact
Uber’s CacheFront has delivered remarkable improvements in both throughput and latency:
- Enabled over 40 million reads per second across services.
- Cut P75 latency by 75% and reduced P99.9 latency by over 67%, drastically enhancing user experience and system responsiveness.
Conclusion
Uber’s approach to integrated caching proves that speed and accuracy can coexist at massive scale. By combining:
- Redis-based caching
- Real-time change detection
- Smart multi-region design
Connect With Us
At FyndMyAI we’re spotlighting innovators with free thought leadership features + social collabs. DM us to claim your spotlight.
Check out the top 5 AI Tools for writing blogs